

Discord đã thiết lập Elasticsearch như thế nào để có thể index hàng tỷ messages?
Discord tuy sinh sau đẻ muộn so với các ông lớn khác nhưng là một trong những ứng dụng chat được sử dụng rộng rãi, đặc biệt trong gaming. Một điều thú vị là ở Discord, họ sử dụng Elasticsearch cho việc index và search các messages. Vậy Discord đã index hàng tỷ messages của họ như thế nào?

Trong quá trình mình tìm hiểu về Elasticsearch, mình đã đọc qua bài viết này của Discord, chia sẻ về cách mà họ thực hiện index hàng tỷ messages nhằm phục vụ chức năng tìm kiếm (search) messages trong group. Bài viết How Discord Indexes Billions of Messages được chia sẻ ở đầu năm 2017, tức khoảng 2 năm sau khi Discord release (Discord release vào năm 2015).
1. Overview
1.1. Server / Channel / Message
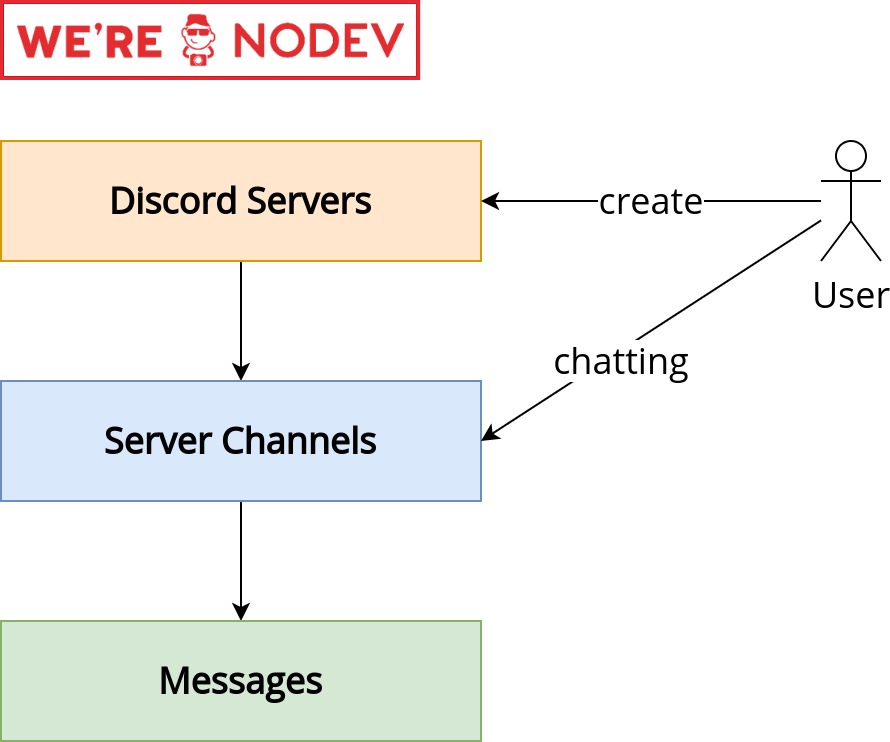
Đầu tiên mình muốn làm rõ về hệ thống lưu trữ người dùng, group và message ở Discord. Discord lưu trữ messages người dùng ở 3 layer (3 lớp lưu trữ). Cụ thể khái niệm group ở Discord được định nghĩa là server hay guide. Khi người dùng tham gia vào Discord, họ sẽ có thể tạo ra các group (server) riêng mà họ muốn, và thực hiện mời bạn bè gia nhập.
Trong mỗi server, Discord chia ra thành nhiều channel, ở mức channel này, người dùng mới có thể thực hiện chat với nhau, tức gửi message. Do vậy, message ở Discord được lưu trữ ở tầng channel thay vì tầng server.
Mô hình lưu trữ messages này được minh họa như hình bên dưới
1.2. Database
Vấn đề tiếp theo mà mình muốn đề cập chính là lưu trữ messages ở Discord như thế nào. Theo bài viết cũng do Discord chia sẻ, How Discord Stores Billions of Messages, họ lưu trữ messages dùng cơ sở dữ liệu Cassandra.
Theo như Discord chia sẻ, họ đã chuyển từ MongoDB sang Cassandra để scale hệ thống khi mà lượng messages đã tăng lên quá nhanh.
2. How Discord setup Elasticsearch?
2.1. Indexing
Việc index messages ở Discord được thực hiện theo mô hình dưới đây:
- Sử dụng một số worker để index các messages cũ từ database, gọi là Historical Index Worker. Một lưu ý ở bước này chính là tính iterable. Discord sử dụng database là Cassandra và có khả năng iterate các messages cũ một cách hiệu quả mà không ảnh hưởng đến performace hiện tại của hệ thống.
- Sử dụng các worker khác thực hiện index các messages mới từ người dùng bằng Message Queue. Message Queue không được Discord đề cập trong bài viết, tuy nhiên chúng ta có thể thay thể hoặc tin tưởng vào Kafka hoặc RabbitMQ.

Thêm một điều nữa là Discord tuân theo triết lý Lazily Indexed, tức không thực hiện index nếu không có hành động search từ người dùng. Việc này đảm bảo những gì được index là những gì được search.
2.2. Discord Sharding
Việc sharding ở Discord là một tinh hoa trong bài viết mà họ chia sẻ. Tuy nó không hẳn phù hợp trong mọi ngữ cảnh nhưng đó là một thiết kế chúng ta có thể học hỏi và tiếp thu.
2.2.1. Shard Definition
Như chúng ta biết, Elasticsearch thực hiện sharding các index ra nhiều primary shards, mỗi primary shards có thể được replicated hoặc không tùy mục đích sử dụng của người dùng. Mỗi index sẽ được sharding ra nhiều shard dựa trên một routing key, mà mặc định chính là docID. Mục tiêu sử dụng Elasticsearch ở Discord chính là search messages theo từng group (hay server). Do đó nếu sử dụng sharding từ Elasticsearch, chúng ta có thể nghĩ đến việc sử dụng groupID (serverID) làm routing key, từ đó đảm bảo mọi messages trong một group sẽ nằm trên một shard nhất định.
Ở Discord, khái niệm Shard đã được thay đổi, không sử dụng cơ chế sharding như Elasticsearch. Họ thực hiện sharding ở tầng application. Mỗi một shard ở Discord tương ứng là một cặp Cluster - Index, tương ứng với cluster và index trên cluster đó. Lúc này, index của họ chỉ sử dụng 1 primary shards duy nhất, điều đó đảm bảo sharding của họ có ý nghĩa.
Cơ chế sharding có họ được thực hiện như sau:
- Mapping tương ứng mỗi một groupID với một cặp Cluster - Index.
- Persistent Shard Mapping: sử dụng một database để thực hiện mapping. Cụ thể dùng cassandra để lưu persist việc mapping.
- Shard Mapping Cache: dùng Redis cache việc mapping, nhằm speed up việc truy xuất mapping khi lượng groups quá lớn.

2.2.2. Shard Allocator
Câu hỏi đặt ra cho Discord là họ sẽ thực hiện mapping một groupID với một cặp Cluster - Index như thế nào? Cụ thể khi thực hiện index một groupID, Discord cần dùng tiêu chí nào để chọn ra một cluster-index phù hợp.
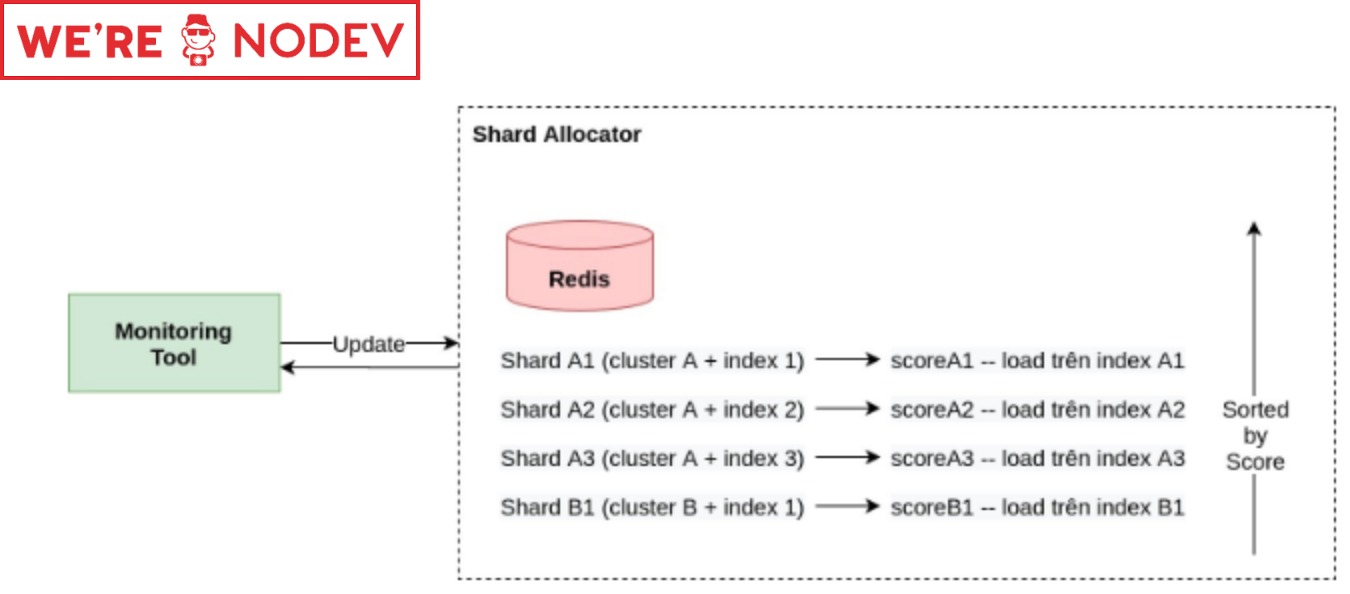
Cách mà Discord giải quyết câu hỏi này chính là sử dụng một bộ Shard Allocator mà ở đó, dựa trên mức tải (load) trên một index (1 shard) để chọn ra index có mức load tối thiểu và ổn định. Việc này khá đơn giản, sử dụng một bộ monitor hợp lý cùng với một database hoặc một service đơn giản là có thể thực hiện việc này.
Theo như Discord chia sẻ, họ sử dụng Redis làm nơi lưu trữ các metrics monitor được từ các clusters và indices, lưu trữ các metrics này theo sortedset nhằm sắp xếp và truy xuất bộ (cluster-index) nhanh nhất. Chúng ta có thể ước tính lượng keys trên tập data này (hay lượng indices thực thế được sử dụng) là đủ nhỏ (từ vài trăm đến vài chục ngàn tùy theo độ lớn messages).
2.3. Search
Như vậy Discord thực hiện search như thế nào với cách thiết kế như mình đã đề cập?
Discord dựa trên groupID, tức serverID, dựa trên bộ Shard Mapping để xác định được Cluster-Index tương ứng. Dựa trên keywords mà người dùng tìm kiếm, Elasticsearch trả về danh sách các messageID có liên quan đến từ khóa. Discord dựa trên messageID thực hiện truy vấn sáng database để lấy các thông tin và trả về cho client.
Ở đây cần lưu ý, Discord không thực hiện lưu trữ các thông tin khác của messages trong Elasticsearch, mà chỉ lưu trữ messageID, serverID và channelID. Bởi vì Discord không muốn tốn chi phí lưu trữ khi đã sử dụng database khác để lưu trữ những messages này. Một trade-off chúng ta nhận thấy là việc truy xuất DB để có được thông tin messages.
2.4. Cluster Size
Dưới đây là một só thông số về lượng lớn dữ liệu tại Discord được lưu trữ. Đây là những thống kê không chính thức mà mình tìm được từ các nguồn khác. Tuy nhiên có thể thấy được độ lớn của dữ liệu cũng như tính ổn định và hiệu quả mà Elasticsearch được sử dụng tại Discord.
Năm 2017 trong 2 tháng
2clusters14nodes26 tỷdocuments16kindices- Hàng triệu groups
Giữa 2018:
~ 130mgroups~ 530mmessages/day
Giữa 2020:
~ 250mgroups~ 963mmessages/day
3. Conclusion
Đây là những chia sẻ về cách mà Discord sử dụng Elasticsearch như thế nào mà mình đã đọc và hiểu được. Có thể bài viết chưa thực sự đầy đủ và hiểu được hết những tinh hoa bên trong mà Discord đề cập, nhưng mình nghĩ đây cũng là nhưng bài học đáng quý cho những ai đã/đang/sẽ chuẩn bị sử dụng Elasticsearch cho một ứng dụng chat (hoặc tương đồng).
Để có thể hiểu rõ hơn và chi tiết hơn về những chia sẻ từ Discord, vui lòng xem trong bài blog How Discord Indexes Billions of Messages.